SageでTheanoのロジスティック回帰を試す
参考サイト
ここでは、 人工知能に関する断創録 のTheanoに関連する記事をSageのノートブックで実装し、Thenoの修得を試みます。
今回は、Theanoのロジスティック回帰を以下のページを参考にSageのノートブックで試してみます。
2値分類
2値分類とは、入力xの値によって2種類に区別する問題です。2値の変数$y \in {0, 1}$で表現した場合、 入力xからyの値を推定します。
入力xを指定したとき、y=1となる事後確率$p(y=1|x)$をニューラルネットを使ってモデル化します。活性化関数gにはロジスティック関数を使用します。 $$ h(x) = p(y=1|x) \approx g(x; w) $$ $$ g(z) = \frac{1}{1 + e^{-z}} $$
べき乗の性質を使ったトリックを使うと事後分布$p(y|x; w)$をy=1とy=0の分布を使って $$ p(y|x) = p(y=1|x)^y p(y=0|x)^{1-y} $$ と表すことができます。ここで$p(y=0|x) = 1 - h(x)$であることを使うとwの尤度は、 $$ L(w) = \prod_{n=1}^N p(y_n | x_n; w) = \prod_{n=1}^N \{ h(x_n)\}^{y_n} \{1 - h(x_n) \}^{1-y_n} $$ で与えられ、負の対数尤度は、以下のようになります。 $$ E(w) = - \sum_{n=1}^N [y_n log h(x_n) + (1-y_n) log\{1 - h(x_n)\}] $$
必要なライブラリをインポート
最初に使用するライブラリをインポートします。
|
|
訓練データのロード
訓練データex2data1.txtをDATAディレクトリから読み込みます。
|
|
データの分布
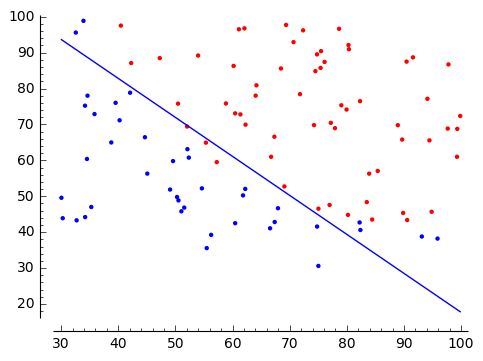
y=1を赤、y=0を青の●(point)でプロットし、データの分布をみます。
SageのGraphicsとpointを使うと簡単にデータの分布が可視化することができます。

|
コスト関数の自動微分
バイアス項もwに追加するために、入力データxの1列目に1の列を追加します。
従って重みwは、$ w = [w_0, w_1, w_2]$となります。
Theanoでコスト関数で定義します。
- X: 訓練データを表す共有変数
- y: 訓練データの正解ラベルを表す共有変数
- w: 重み(パラメータ)を表す共有変数
g_wは、コスト関数をパラメータwで微分した数式を表している。 このようにとても簡単に微分を定義することができるのがTheanoの特徴です。
|
|
|
|
Theanoによる勾配降下法の実装
学習率learning_rateと更新updatesにwの更新を定義し、theanoのfunctionとしてtran_modelを定義して、 これを繰り返し実行するだけで勾配降下法が実現できてしまうところが本当にすごいです。
# 訓練用の関数を定義 train_model = theano.function(inputs=[], outputs=cost, updates=updates)functionで指定したupdatesは、関数の実行後に指定された更新が自動的に行われる仕組みになっており、 updatesには(共有変数, 更新式のシンボル)のペアが並ぶリストを指定します。
train_modelの戻り値には、cost関数の戻り値が返されます、これを収束の判定に使うことができます。
今回は収束判定はしないで、30万回パラメータの更新を繰り返します。
|
|
0 0.69314718056 20000 0.547295463694 40000 0.488295709188 60000 0.445118809496 80000 0.41259440171 100000 0.387389522711 120000 0.367353248365 140000 0.351070505109 160000 0.337586093857 180000 0.326237734121 200000 0.316554335209 220000 0.308192817261 240000 0.300897944917 260000 0.294476164256 280000 0.288778154733 0 0.69314718056 20000 0.547295463694 40000 0.488295709188 60000 0.445118809496 80000 0.41259440171 100000 0.387389522711 120000 0.367353248365 140000 0.351070505109 160000 0.337586093857 180000 0.326237734121 200000 0.316554335209 220000 0.308192817261 240000 0.300897944917 260000 0.294476164256 280000 0.288778154733 |
結果をプロット
求められた重みwからy=0とy=1の境界を求めます。 $$ w_0 + w_1 x_1 + w_2 x_2 = 0 $$ から $$ x2 = -w_0/w_2 - w_1/w_2 x_1 $$ となります。これをSageのPlot関数を使って表示してみましょう。
w: [-9.25573205 0.07960975 0.07329322] w: [-9.25573205 0.07960975 0.07329322] |
|
Theanoによる確率的勾配降下法の実装
上記の勾配降下法は、誤差関数に各サンプルの誤差$E_n(w)$の和を求めています。この方法をバッチ学習(batch leaning)と呼びます。 $$ E(w) = \sum_{n=1}^N E_n(w) $$
これに対してサンプルからランダムに1個を抽出し、パラメータの更新を行う方式を確率的勾配降下法(stochastic gradient descent) と呼び、SGDと略します。SGDでのwの更新は以下のように行われます。 $$ w^{(t+1)} = w^{(t)} - \epsilon \Delta E_n $$
TheanoでSGDを実装するには、更新式を少し書き替えるだけで実現できます。
# 訓練データのインデックスを表すシンボルを定義 index = T.lscalar() # コスト関数の微分をindex番目のデータのみ使うように修正 h = T.nnet.sigmoid(T.dot(w, X[index,:])) cost = -y[index] * T.log(h) - (1 - y[index]) * T.log(1 - h) # 訓練用の関数の定義で、inputにindexを指定し、index番目の訓練データのみを使ってパラメータ更新する train_model = theano.function(inputs=[index], outputs=cost, updates=updates)
人工知能に関する断創録では、5000で計算していましたが、解がばらばなので、10000に増やして計算してみました。
|
|
|
|
|
|
0 0.00626922875529 500 0.00485145163942 1000 0.00343694092133 1500 0.0022905693827 2000 0.00152623463524 2500 0.00104524690395 3000 0.000740921403039 3500 0.000543269844235 4000 0.000410742254143 4500 0.000318971253672 5000 0.000253433498711 5500 0.000205278966195 6000 0.000168987784349 6500 0.000141027487384 7000 0.000119073494346 7500 0.000101552514181 8000 8.73712531876e-05 8500 7.57516531313e-05 9000 6.61281421697e-05 9500 5.80817939699e-05 w: [-15.15362536 0.14347172 0.14670372] 0 0.00626922875529 500 0.00485145163942 1000 0.00343694092133 1500 0.0022905693827 2000 0.00152623463524 2500 0.00104524690395 3000 0.000740921403039 3500 0.000543269844235 4000 0.000410742254143 4500 0.000318971253672 5000 0.000253433498711 5500 0.000205278966195 6000 0.000168987784349 6500 0.000141027487384 7000 0.000119073494346 7500 0.000101552514181 8000 8.73712531876e-05 8500 7.57516531313e-05 9000 6.61281421697e-05 9500 5.80817939699e-05 w: [-15.15362536 0.14347172 0.14670372] |
決定境界の表示
解は勾配降下法の線の当たりをばらつきます。
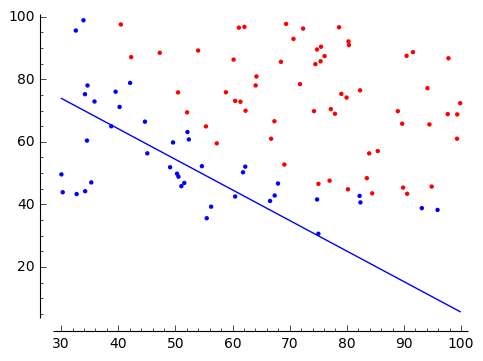
|
|
|