Sageでグラフを再現してみよう:データ解析のための統計モデリング入門第4章
この企画は、雑誌や教科書にでているグラフをSageで再現し、 グラフの意味を理解すると共にSageの使い方をマスターすることを目的としています。
前回に続き、データ解析のための統計モデリング入門 (以下、久保本と書きます) の第4章の例題をSageを使って再現してみます。
4章のメインは、久保本図4.9(以下に引用)のバイアス補正とその分布にあると思います。

数式処理システムSageのノートブックは、計算結果を表示するだけではなく、実際に動かすことができるの大きな特徴です。 この機会にSageを分析に活用してみてはいかがでしょう。
前準備
最初に必要なライブラリーやパッケージをロードしておきます。
|
|
あてはまりの良さとモデルの複雑さ
「あてはまりの良さとモデルの複雑さ」を説明するために、3章のデータを使ってk=1とk=7の結果の比較が示されています。 このような図を簡単に再現できれば、実際の分析の時にも役立つと思います。
3章のデータをも一度読み込み、statsmodelsのglmを使ってk=1とその結果をプロットします。
|
|
|
|
|
|
<ggplot: (8752412588061)> <ggplot: (8752412588061)> |
Saving 11.0 x 8.0 in image. Saving 11.0 x 8.0 in image. |

多次元(poly)のglmは、statsmodelsではできない
次にk=7($log \lambda = \beta_1 + \beta_2 x + ... + \beta_7 x^6$)の計算ですが、 残念ながら、statsmodelsは、線形項の多次元のglmをサポートしていないので、Rのglmを使って図化してみます。
Rのggplot2には、geom_smoothというlmやglmの計算結果を使ってスムーズ曲線を描画する機能があります。 これを使ってk=7の結果を表示してみましょう。線形項の多項式は、poly関数を使うと便利です。
Sage(Pandas)とRのデータフレームを相互に変換したり、Rの結果をSageで図化する関数をRUtilで定義してあるので、 ともて簡単にk=7の結果を図化できます。
k=1とk=7の結果をみるとk=7の結果は、あまりにも複雑な曲線を示しており、機械学習でいうところの「過学習」 (Overfitting)の状態になっています。過学習では、学習用データ(ここでいうサンプルデータ)に引きずられ、 真のモデルから離れてしまいます。
|
|

さまざまな逸脱度
逸脱度は、「あてはまりの悪さ」を表現する指標と久保本では説明されています。
最大対数尤度を$log L^*$とすると、逸脱度(D)は以下の様に定義されます。 $$ D = -2 log L^* $$
4章で登場する逸脱度を以下の表に示します。 最大の逸脱度は、一定モデルで、最小の逸脱度はフルモデルです。
|
各モデルのglmのfit結果を求めて、その結果を表にまとめます。
ここで出てくるモデル選択の基準となるAIC(Akaike's information criterion)は、以下の様に定義されています。 $$ AIC = -2 { (最大対数尤度) - (最尤推定したパラメータの数)} = D + 2k $$
|
|
データの個数と同じ数のパラメータを使ってあてはめたモデルがフルモデルです。 これは、実際にそのようなモデルを作って計算するのでは無く、フルモデルはすべての観測値が予測値と一致するモデルであり、 その結果、残差は0であり、対数尤度は、以下のようになります。
-192.889752524496 -192.889752524496 |
結果をみやすくするために、小数点以下3桁を表示する関数prf3を定義します。
|
|
|
平均対数尤度を使ったモデルの予測の良さ
いよいよ図4.9の計算に入ります。久保本ではモデル選択の指標としてAICが使えるのかを一定モデルを使って 数値例で示しています。(これが久保本のすごいところ!)
平均の対数尤度は、真のモデルを使って生成されたサンプルから求めた対数尤度の平均値であり、実際のモデルづくりでは このようなことは不可能ですが、平均対数尤度と推定されたモデルの関係とこの差(バイアス)bの分布からAICの意味するところを 表現しています。bの定義は以下の通りです。 $$ b = log L^* - E(Log L) $$
観測データが一つの場合
図4.9の(A)観測データが一つの場合について、真のモデルλ=8のポアソン分布から50個のサンプルを生成します。
準備としてサンプル生成関数genSample, 対数尤度を計算するlogLを定義します。
|
|
|
|
|
|
glmを使って一定モデルの結果を取得します。ここでは対数尤度が-119.6、 $\beta_1$の値は2.001と求まりました。
|
|
-125.051229132 2.1377104498 -125.051229132 2.1377104498 |
この結果を図化し、logL_pltにセットします。
|
|
つぎに、真のモデルから50個のサンプルを200セット生成し、平均の対数尤度を計算します。
|
|
求まった結果を一つにプロットします。logL*を赤○で、平均対数尤度を緑○で、各対数尤度を小さな青○で示し、 各βの対数尤度曲線と一緒に表示したのが、以下の図です。
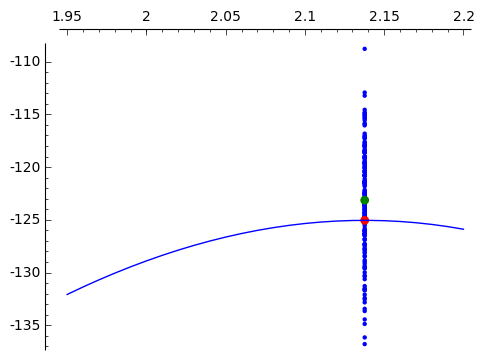
|
|
|
繰り返しは簡単
次に上記の処理を繰り返した図4.9(B)を試してみます。 Sageでは、一度試した処理をコピー&ペーストしてループに入れたり、関数にすることで結果を確認しながら 処理を進めることで効率良く目的のグラフを得ることができます。
最初に空のGraphics=gを生成し、上記の処理と同じことをして、プロット結果をgに加えていきます。 たったこれだけで、図4.9の(B)が再現できます。
久保本では、平均対数尤度が結構きれいな曲線で表示されていますが、私の計算ではぶれています。
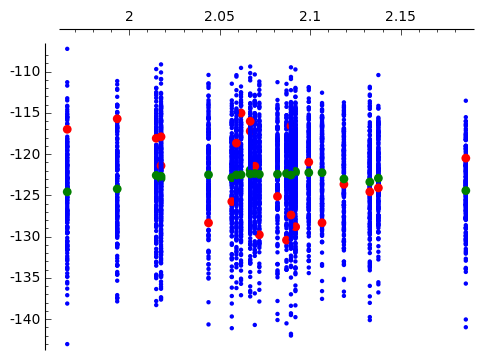
|
バイアスbの計算
時間がかかったので、200セットのデータに対してバイアスbを計算し、その分布を表示してみました。
バイアスbは、0.7と久保本の1.01とはずれています。
|
|
|
|
1.071531596453642 1.071531596453642 |
stat_bin: binwidth defaulted to range/30.
Use 'binwidth = x' to adjust this.
/usr/local/sage-6.7/local/lib/python2.7/site-packages/pandas-0.15.2-py2.\
7-linux-x86_64.egg/pandas/util/decorators.py:81: FutureWarning: the
'rows' keyword is deprecated, use 'index' instead
warnings.warn(msg, FutureWarning)
<ggplot: (8752413086621)>
stat_bin: binwidth defaulted to range/30.
Use 'binwidth = x' to adjust this.
/usr/local/sage-6.7/local/lib/python2.7/site-packages/pandas-0.15.2-py2.7-linux-x86_64.egg/pandas/util/decorators.py:81: FutureWarning: the 'rows' keyword is deprecated, use 'index' instead
warnings.warn(msg, FutureWarning)
<ggplot: (8752413086621)>
|
Saving 11.0 x 8.0 in image. Saving 11.0 x 8.0 in image. 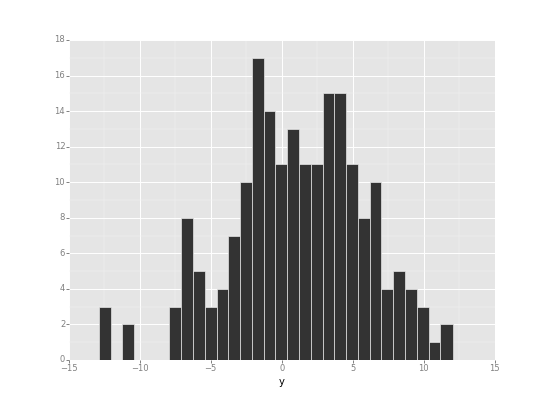
|
Rで計算
久保本のサポートページにあるRの関数を使ってサンプル1000セットでバイアスbを計算してみました。 これでも 1.213と計算され、その分布をみると-20から20の区間でかなりぶれていることがわかります。
バイアスの定義を変形すると、平均対数尤度$E(logL)$は以下の様になります。 $$ E(log L) = log L^* - b $$ ここで、一定モデルのk=1であることからバイアスbとkを入れ替えるとAICの定義となり、 AICが予測の「悪さ」を表す指標となっていることがうなずけます。 $$ AIC = -2 \times (log L^* -1) $$
また、上記の数値実験の結果得られたバイアスb=1という値は、かなりぶれることも分かりました。
$value
function (lambda.true, sample.size)
{
sample.rpois <- rpois(sample.size, lambda.true)
fit <- glm(sample.rpois ~ 1, family = poisson)
lambda.estimated <- exp(coef(fit))
likelihood.mean <- mean(sapply(1:200, function(i) {
sum(log(dpois(rpois(N, lambda.true), lambda.estimated)))
}))
logLik(fit) - likelihood.mean
}
$visible
[1] FALSE
$value
function (lambda.true, sample.size)
{
sample.rpois <- rpois(sample.size, lambda.true)
fit <- glm(sample.rpois ~ 1, family = poisson)
lambda.estimated <- exp(coef(fit))
likelihood.mean <- mean(sapply(1:200, function(i) {
sum(log(dpois(rpois(N, lambda.true), lambda.estimated)))
}))
logLik(fit) - likelihood.mean
}
$visible
[1] FALSE
|
[1] 0.9048361 [1] 0.9048361 |
|
|

|
|