Sageでグラフを再現してみよう:階層ベイズ法
この企画は、雑誌や教科書にでているグラフをSageで再現し、 グラフの意味を理解すると共にSageの使い方をマスターすることを目的としています。
今回は、道具としてのベイズ統計 のp196の学生のテスト結果を階層ベイズ法を使って表現した図を題材にします。

|
|
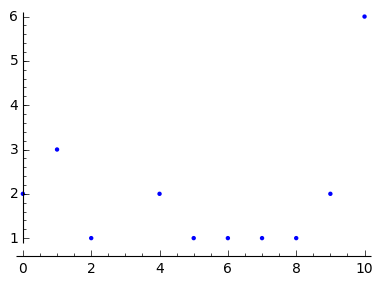
データの度数分布
学生のテスト結果は、10点満点中、Xのような得点になっています。
これまで、度数分布図はRを使っていましたが、点数毎のカウント数を保持する辞書型変数を plot関数に渡すと度数分布が表示されることが分かりました。
[1] 20 [1] 20 |
度数を計算する関数_mkHist
度数を計算する関数_mkHistを以下のように定義します。 処理は、データの値毎にカウント数をアップしているだけです。 ポイントとしては、hist.setdefaultを使って要素が未定義 の場合に、0をデフォルト値としているところです。
作成した度数分布図をhist_plt変数に保持しておきます。
|
|
|
階層ベイズ計算プログラムJAGSをRから使う
階層ベイズのギブス・サンプリングを行うプログラムJAGSをRから使うためのライブラリ を呼び込みます。
rjagsについては、singular piont氏の「 JAGSを使ってギブスサンプリングを試してみた 」を参考にしました。
[1] "rjags" "coda" "jsonlite" "ggplot2" "stats" "graphics" "grDevices" "utils" [9] "datasets" "methods" "base" [1] "rjags" "coda" "jsonlite" "ggplot2" "stats" "graphics" "grDevices" "utils" [9] "datasets" "methods" "base" |
二項分布の場合
学生の持つ問題解決能力をq(皆同じ値と仮定)とすると、i番目の学生が10点満点中k点を取る確率$p_i$は以下のようになります。 $$ p_i = {}_{10} C_k q^k (1 - q)^{10 - k} $$
jagsモデル定義
jagsのモデルファイルは、とても簡単です。
i番目の学生得点は、dbin(q, 10)に比例し、 $$ x_i \sim dbin(q, 10) $$ 問題解決能力をqは、一様分布dunif(0, 1)に比例すると仮定します。 $$ q \sim dunif(0, 1) $$
これをJAGSのモデルで記述すると、以下のようになります。(とてもストレートで読みやすいと思いませんか)
model {
for (i in 1:N) {
x[i] ~ dbin(q, 10)
}
q ~ dunif(0,1)
}
model {
for (i in 1:N) {
x[i] ~ dbin(q, 10)
}
q ~ dunif(0,1)
}
|
jagsモデルの作成
上記のモデルを使ってjagsのモデルオブジェクトを生成します。
dataとして、学生の得点Xとサンプル数Nを渡します。
n.chainsで4つのチェインを指定し、n.adapt=1000で稼働検査期間(buring in period)を1000と指定します。
|
|
mcmcサンプリング
サンプリングには、jagsをそのまま使うのではなく、codaを使ってサンプリングを行います。 これによって、サンプリング後の収束判定や変数の分布図のプロット等がとても簡単になります。
coda.samplesの引数で、サンプリングする変数名qとサンプリング数1000を指定します。
|
|
サンプリング結果の出力
summary関数を使ってサンプリング結果を出力します。
qの平均値が0.5837391、qの標準偏差が0.0349724と求まっています。
Iterations = 1:1000
Thinning interval = 1
Number of chains = 4
Sample size per chain = 1000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
0.5853766 0.0349785 0.0005531 0.0005426
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.5154 0.5622 0.5858 0.6093 0.6520
Iterations = 1:1000
Thinning interval = 1
Number of chains = 4
Sample size per chain = 1000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
0.5853766 0.0349785 0.0005531 0.0005426
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.5154 0.5622 0.5858 0.6093 0.6520
|
変数の収束状態と分布図の出力
変数の収束を数値で判断する場合には、codaのgelman.plot等を使いますが、 ここでは、plot関数でqのサンプルリング状況とqの密度分布を表示してその収束 具合を表示します。(pdfからpngへの変換に時間がかかるためグラフの例はこれだけにします)
|
|

計算結果をsageに返す方法
jagsの計算結果をsageに戻すには、sageobj関数を使用してsummary結果を sageに渡します。
summaryをsageobjに変換した結果を見やすくしたもの以下に示します。
DATAの中のstatistics辞書に含まれるDATAが結果であることが分かりました。 これを使ってqの統計情報をq_statに代入しています。
|
|
{
'_r_class': 'summary.mcmc',
'_Names': ['statistics', 'quantiles','start', 'end', 'thin', 'nchain'],
'DATA': {'start': 1,
'quantiles':{
'_Names': ['2.5%', '25%', '50%', '75%', '97.5%'],
'DATA':[0.513481769858723, 0.559770434697337, 0.583772200385166,0.607076674579427, 0.650723254372329]
},
'statistics': {'_Names':['Mean', 'SD', 'Naive SE', 'Time-series SE'],
'DATA':[0.583363967387052, 0.034643219966608, 0.000547757402883519,0.000513408728594538]
},
'end': 1000,
'thin': 1,
'nchain': 4
}
}
[0.585376562260118, 0.0349785415809423, 0.000553059303133422, 0.000542561724291984] [0.585376562260118, 0.0349785415809423, 0.000553059303133422, 0.000542561724291984] |
二項分布図
jagsを使ったギブス・サンプリングで求まったqを使って学生の得点確率pの確率分布を表示してみます。
_pで二項分布を定義し、0から10までの得点の確率分布(赤の線)を以下に示します。
学生の問題解決能力をqを一定としたために、分布が学生の得点分布をうまく表現できていません。
|
|

|
個人の学習能力を考慮したモデル
そこで、個人の学習能力にばらつきがあると仮定したモデルを作成します。
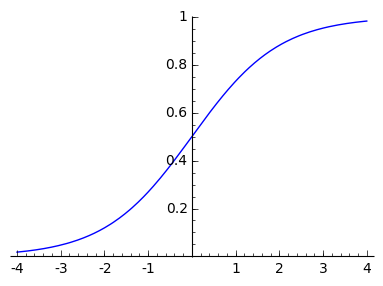
学生iの問題解決能力を$q_i$とし、$q_i$が以下の学習曲線で変化すると仮定します。
この学習曲線をロジットモデルと呼び、以下の式で表されます。 $$ log\frac{q_i}{1 - q_i} = \beta + \gamma_i $$
学生の問題解決能力は、クラスの全体の平均的な理解度合い$\beta$とそれからのずれ $\gamma_i$(これを個人の理解度と呼ぶことにしましょう)
|
ハイパーパラメータ
個人の理解度正規分布を持つと仮定し、この事前分布$\pi(\gamma_i | \sigma)$を以下のように定義します。 $$ \pi(\gamma_i | \sigma) \sim \mathcal{N}(\gamma_i, \sigma) $$
また、$\beta$も正規分布を持つと仮定し、$\sigma$は逆ガンマ分布従うと仮定します。
残念ながらjagsには逆ガンマ分布が提供されていないため、$\tau$のガンマ分布を使って モデルを作成します。 $$ \tau = \frac{1}{\sigma^2} $$
$\tau$の初期分布として、$\gamma(x, 0.1, 0.1)$を使います。 これは、かなり一定値に近い分布となります。

|
個人の学習能力を考慮したモデルのjagsモデル
個人の学習能力を考慮した階層ベイズモデルをjagsの形式で以下に定義します。
x_hat, x_mean, x_sdは、平均の収束度合いを計算するためにチェック用に定義しています。
model {
for (i in 1:N) {
x[i] ~ dbin(q[i], 10)
logit(q[i]) <- beta + gam[i]
gam[i] ~ dnorm(0, tau)
# add for check
x_hat[i] ~ dbin(q[i], 10)
}
beta ~ dnorm(0, 0.0001)
tau ~ dgamma(0.1, 0.1)
# add for check
x_mean <- mean(x_hat)
x_sd <- sd(x_hat)
}
model {
for (i in 1:N) {
x[i] ~ dbin(q[i], 10)
logit(q[i]) <- beta + gam[i]
gam[i] ~ dnorm(0, tau)
# add for check
x_hat[i] ~ dbin(q[i], 10)
}
beta ~ dnorm(0, 0.0001)
tau ~ dgamma(0.1, 0.1)
# add for check
x_mean <- mean(x_hat)
x_sd <- sd(x_hat)
}
|
個人の学習能力を考慮したモデル実行
先ほどと同様にjagsモデルを作成し、サンプリングを実行します。
サンプリングで取り出すのは、x_mean, x_sd, q, beta, tauとします。
|
|
|
|
計算結果
計算結果は、先ほどとは異なり、24x4のマトリックスとして返されます。
それをsageのbeta, q, tau, x_mean, x_sdにセットしています。
x_meanが5.84929375、x_sdが3.79893738478という値は、 実データの平均5.9と標準偏差3.80とよく一致しています。
|
|
24 x 4 dense matrix over Real Double Field (use the '.str()' method to see the entries) 24 x 4 dense matrix over Real Double Field (use the '.str()' method to see the entries) |
5.84935 3.80367564351 1.04177501917 0.0990313011176 [0.128545996572833, 0.0461399891946393, 0.966660391533606, 0.412615502206996, 0.96577610027946, 0.96624425853242, 0.96591491188521, 0.600899014260124, 0.412010328604094, 0.96612292192937, 0.130550762521106, 0.88413882093641, 0.0460301328643418, 0.508155415202037, 0.966515880580117, 0.701063599292567, 0.129718522044942, 0.885115788434058, 0.22112061176942, 0.793587836419095] 5.84935 3.80367564351 1.04177501917 0.0990313011176 [0.128545996572833, 0.0461399891946393, 0.966660391533606, 0.412615502206996, 0.96577610027946, 0.96624425853242, 0.96591491188521, 0.600899014260124, 0.412010328604094, 0.96612292192937, 0.130550762521106, 0.88413882093641, 0.0460301328643418, 0.508155415202037, 0.966515880580117, 0.701063599292567, 0.129718522044942, 0.885115788434058, 0.22112061176942, 0.793587836419095] |
期待得点分布
個人の理解度$\gamma$を持つ学生が得点xを取る確率は、以下のようになります。 $$ f(\beta, \sigma, \gamma | x) = {}_{10} C_x q^x (1 - q)^{10-x} \frac{1}{\sqrt{2 \pi}\sigma} e^{- \frac{\gamma^2}{2 \sigma^2}} $$
これを$\gamma$で積分したものが、学生が得点xを取る確率になります。 $$ f(\beta, \sigma | x) = \int f(\beta, \sigma, \gamma | x) d \gamma $$
sage$f(\beta, \sigma, \gamma | x)$を関数_r(x, b, r, sig)に定義します。
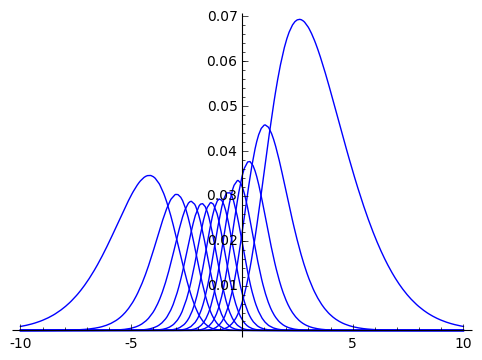
また、x=0~10までの各分布を以下にプロットします。プロットの結果から分布の積分を求めるには、 -20から20の範囲で数値積分すれば良いことが読み取れます。
|
|
|
$f(\beta, \sigma | x)$を求める
Sageの最大の武器はその数式処理能力です、ここでは数値積分関数(numerical_integral)を 使って$f(\beta, \sigma, \gamma | x)$を数値積分します。
|
|
求める図のプロット
ようやく求める図をプロットするのに必要な道具が揃いました。
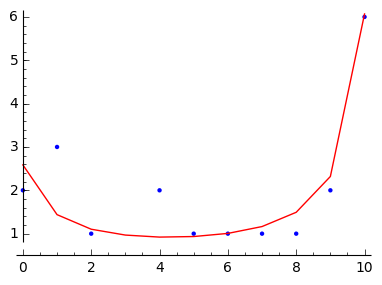
数値積分は、_rInt関数で行い、xが0から10までの$f(\beta, \sigma, \gamma | x)$の 値をプロットし、度数分布図と重ねて表示したのが、以下の図です。
このようにSageとjagsの組み合わせによって通常の処理形では難しい階層ベイズ推定を 使ったモデルの解析がとても簡単にできることがご理解頂けと思います。
これを機会に是非Sageとjagsを使ってみてください。
|
|
|